
Machine Learning is ingrained in our day-to-day life. It is part of our spam filters mechanism, voice command smartphone interpretation and any search on Google. Alexa, what time is it? Chances are good that machine learning has been helping you along somewhere in your life. This is a short blog on Machine Learning 101. So what is machine learning? Machine learning exists at the intersection of computer science and statistics.
Let’s start with some basic machine learning 101 concepts :
Before looking at machine learning models or even starting with data collection, one should define the problem that needs to be solved. Remember that eventually, a computer program should look into data, measure values and predict some results. A clear problem definition will prevent using the wrong machine learning tools or data sets.
Preparing and understanding the data set before using it is always important. It becomes critical when dealing with machine learning and big data. Each small mistake can lead to a huge impact on the expected results. More data is not always better results.
There are times when more data helps; there are times when it doesn’t.
Since the sample size effects the computation resource requirement, there are times when more data helps; there are times when it doesn’t.
Machine learning leverages a group of tools and techniques for multiple types of problems. Picking the right tool is essential, once you have defined the problem and identified the existing data set. Remember, machine learning is always about estimation and making the best guess, so don’t expect perfect results. There is always a margin of error, noise, correlation coefficient and other such imperfections. So Machine learning is also about trial and error.
Here are few technical machine learning 101 terms you should be aware of:
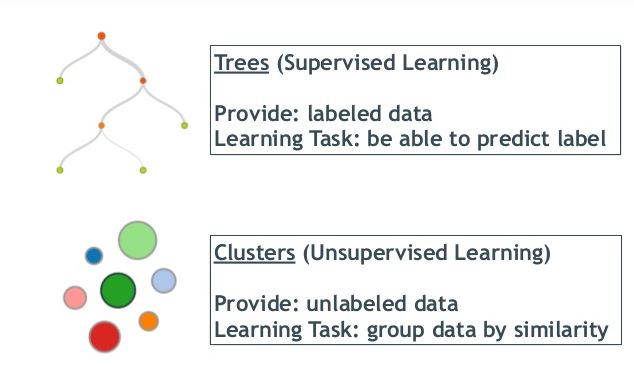
Supervised Learning – When data points have “labels” assigned to them to “teach” the expected output per input. The algorithm will train on the labeled data and predict labels for new inputs.
Unsupervised Learning – no labels are available for training the algorithm, leaving it on its own to find structure in its input.
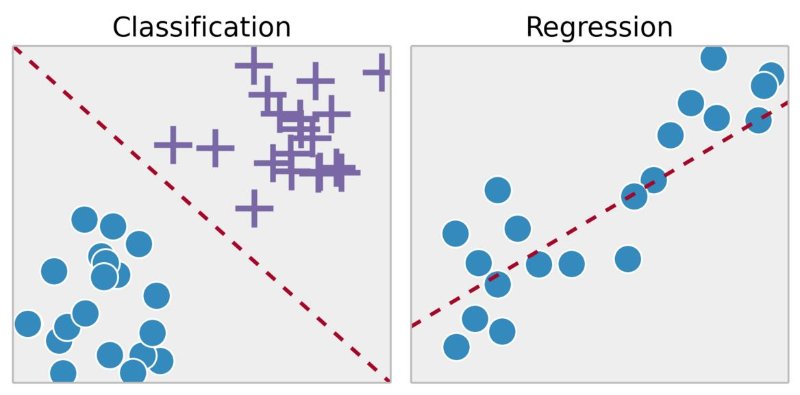
Classification is when the results should be 1 of n values, and each wrong prediction is equally wrong. For example, if you’re trying to classify images of items, identifying a cat as a house isn’t any better or worse than identifying a dog as a house. With classification, the output variable takes class labels (in our example – house, cat, dog).
Machine learning focuses on prediction, based on known properties learned from the training data.
Regression is used when there’s some sense of distance between the values. For example, if the actual value of market stock is $150 and you predicted it to be $149.4, that’s a pretty good prediction, while $10 is a much worse prediction. With regression the output variable takes continuous values (in our example what should be the market stock value).
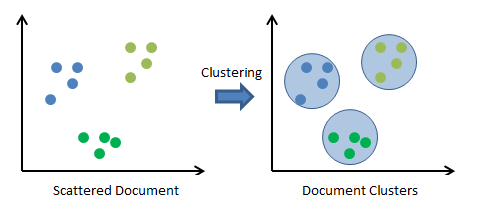
Similar to classification, in clustering we’re trying to group the data, only that the data is not labelled beforehand. Clustering looks at correlation to see if the data can be divided into groups based on similarity.
Since clustering has no predefined labels, it uses unsupervised learning methods for the training period.
Many modern machine learning problems take multiple dimensions of data to build predictions using many coefficients. Dimensionality Reduction simplifies data processing by mapping them into a lower-dimensional space. In many cases non-numeric values should be converted to number values before going on a dimensional reduction phase.
The last lesson in Machine Learning 101 is: present your results! Make sure you present them in a visually compelling, understandable manner.
Whatever results you get, validate those on real “outside” data. Internal testing can’t replace an actual production environment.
In most cases machine learning “consumers” are not data scientists nor do they have any expertise in statistics or even knowledge of the data set. The only thing they want is an answer. Example of results could be “77 with 30% margin of error”, “10/90 ratio”, “True / False” and so on. Try playing with the results and present them in simple English words vs convoluted formulas or meaningless numbers.
Consider where the model does not work well or what parts the model does not answer. Go back to the initial problem definition and compare it with the results. Most machine learning algorithms can accept reinforcement and adjustments parameters, for improving the results for future predictions.
Like most fortune-tellers know, presenting the prediction is as important as the prediction itself. Visualization is one of the best ways to present machine learning results. Interactive reports with dashboards and drill down capabilities allow a better understanding of the results.
Before teaching us anything, machine learning should “learn”. As such, the problem definition, data cleanup, model usage and presentation should be well implemented. The results will be amazing!
